
只要有人類的地方就會有惡意言論,而 Facebook 身為全球最大的社交平台,從以往僱用審查團隊去人工檢視,近年來也開始引入 AI 系統來輔助偵測,在 NLP 領域令人振奮的 BERT 系列模型更扮演了關鍵的角色。
本文由黃偉愷, Ke-Han Lu 共同完成,是「人工智慧與大數據之商業價值」這門課的期末報告,我們分成兩大方向調查了 Facebook 在惡意言論偵測的近期發展:
- Facebook Hate Speech Detection:背景介紹及以政策面探討 FB 如何審查、定義惡意言論,AI系統對於目前 FB 的影響
- Facebook BERT-based System:以技術角度介紹 BERT-based 模型的迷人之處及其原理
Facebook Hate Speech Detection
背景介紹
Facebook的創辦人馬克·祖克柏曾說:「Facebook的創建理念是,打造一個全球性的社區,加深人與人之間的聯繫,讓世界上的每個人,都有權利與他人分享他所有的事物」。然而,這看似立意良善的理念,卻淺在著一個問題:「並非所有的使用者都是善良的」。
確實,社群媒體上大部分的使用者都是善良的,單純只是想在社群媒體上與自己的親朋好友分享自己生活中的點點滴滴,透過社群媒體,讓人與人間的聯繫不再因物理上的距離而有所限制,可以輕鬆的在平台上與任何人交換資訊。然而少部分心懷不軌的使用者在社群媒體上散佈各式惡意的內容,試圖去攻擊他人,造成他人身心靈上的創傷。雖然這些用戶佔總體的少數,但社群媒體的資訊傳播速度相對於傳統的口耳相傳來的快上許多,任何資訊都可以在社群媒體上迅速的流傳開來,這也使得內容審核、攔截惡意內容成為重要的課題。平台方應設法在不當內容被傳播開來前就將此內容從平台中移除,保障每位使用者有一個善良和諧的社群環境。
內容審核
人工內容審核
在過往,社群平台處理這些不當內容的方式是透過人工的方式將這些內容移除,因此也產生了一個新的職業:內容審核員。內容審核員多是由來自於一些開發中國家的人員所擔任,他們的任務就是將社群媒體上適當的內容保存,不適當的內容移除,以維持社群網路環境的和諧。由於他們的工作與維持我們生活環境整潔的清潔人員相似,只差在於一個是清理現實世界中的垃圾,一個是清理社群網路中的垃圾,因此也有人將內容審核員的工作稱作為「網路清道夫」。
雖然內容審核員的工作幾乎不需要什麼門檻就可以加入,但相比與現實生活中的垃圾,存在於網路世界中的垃圾比現實生活中的垃圾來的「髒」上許多,而這個「髒」是屬於心靈及精神層面的髒。當人長時間暴露於這樣不當內容的環境中,是很容易會造成自己精神及身心靈上的創傷。也因為這樣這樣特殊的工作性質,通常大公司都會將這些工作外包到一些開發中國家,由那些家庭經濟狀況不佳的社會底層人士所承擔。但由於工資低廉,加上長時間的精神暴力衝擊,部分審查員因此患上心理疾病,甚至是走上絕路,也有的寧可辭職,回去從事垃圾回收的工作,也不願在看到網路上那些不當的垃圾內容。
綜合上述,人工內容審核隱含的缺點,除了對於審核員的精神及心靈創傷外,對於企業來說也會增加人事成本並且人工審核的方式效率較低。上述這些缺點也凸顯出了自動化內容審核的重要性,也許將內容審核的工作交給不會受情感影響並且處理速度快的電腦做會是一個比較好的選擇,一方面可以較有效率的進行內容審核的工作,一方面也可降低公司對內容審核員的需求,減少公司的人事成本,也可降低審核員的心理壓力。
Facebook 的 AI 內容審核[ref]How We Review Content[/ref]
隨著近年來人工智慧、深度學習相關技術的蓬勃發展,尤其是 BERT 家族模型在各式自然語言處理相關任務上大放異彩,刷新了各項成績。在2020年Q4,Facebook使用RoBERTa、XLM、XLM-R 等BERT相關模型所建構的AI系統已經可以做到將 97% 的不當言論內容在被用戶檢舉之前就自動化的偵測出並且移除,相比於2017年Q4的23.6%,可說是有很大的進步。
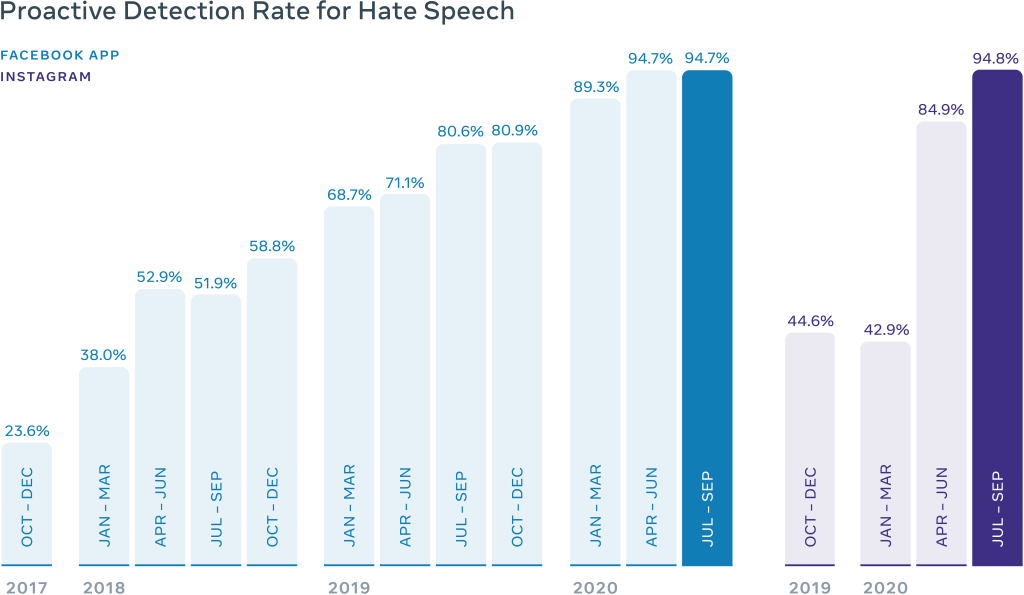
在技術方面,Facebook 的 AI 系統主要在以下三個方面輔助他們進行內容審核的工作[ref]Measuring Our Progress Combating Hate Speech[/ref]:
- Proactive Detection (主動檢測):AI 精確度已達到可在使用者發現並檢舉違規內容前,就自動檢測出各種類型的違規內容並將其移除,保障平台上的使用者不會看到違規的內容。
- Automation (自動化):對於使用者檢舉的內容,在特定情況下,若內容明顯違規 AI 會自動進行判斷並將違規的內容移除。如此可讓審核員更專注於需要更多專業知識才能進行判斷的內容。除此之外,AI 也可自動化判斷被檢舉的內容中是否有重複的,讓審核員可以不用多花時間一直審核重複的內容。
- Prioritization (優先排序):有別於一般依照時間順序進行審合的方式,Facebook 的 AI 系統會先將所有不管來自於使用者檢舉或是系統自動檢測出的違規內容依照嚴重性進行排序,如此便能優先處理那些較嚴重違規、對使用者傷害較大的內容。而在排名的部分是依照內容的傳播性、危害嚴重程度、違規可能性等因素進行排序。對於各個違規內容,若系統可明確判定內容違規,則系統會自動的將此內容從平台中移除。若系統無法明確判定內容是否違規,則會將其交由審核員進行後續審核。
Facebook 的仇恨言論盛行率
仇恨言論盛行率是指使用者在 Facebook 上看到違規內容的次數百分比。計算方式為隨機挑選 Facebook 上的貼文作為實驗樣本,這些樣本內可能會包含來自不同國家、文化背景的使用者所發的貼文,因此 Facebook 會將這些實驗樣本交給來自不同語言、地區的審核員進行審核,判定有多少樣本是違反 Facebook 的仇恨言論政策。根據上述的統計方式,2020 年 7~9 月,Facebook 上的仇恨言論盛行率約為 0.10%~0.11%。這代表每 10000 篇貼文中,大概有 10~11 篇含有仇恨言論的貼文。
誰來決定 Facebook 要保留或刪除的內容?
隨著 Facebook 達到數十億使用者的規模,Facebook 漸漸發現他們不應該再自己做下這麼多關於言論自由及網路安全的重要決定。應該將決策權交給第三方機構才是一個比較好的選擇。因此也誕生了獨立監察團 Oversight Board[ref]Welcoming the Oversight Board[/ref],他的任務為在維護使用者的言論自由權下,協助 Facebook 判定哪些內容該從平台中移除。Oversight Board 對 Facebook 具有約束力,他可以決定要維持或推翻 Facebook 對於內容的處置。在不違反法律的情況下,Facebook 都必須要確實的執行 Oversight Board 在裁決中所要求的事項。
Facebook 對仇恨言論的定義
隨著國家與宗教文化的不同,每個人對於仇恨言論的定義也有所不同。因此要明確的定義什麼是仇恨言論是具有一定難度的。在經過大量的研究以及諮詢各方面專家後,Facebook 將仇恨言論定義為針對受保護的特徵,進行直接攻擊。受保護的特徵指的是種族、民族、國籍、身心障礙、宗教信仰、種姓、性傾向、性別、性別認同和重大疾病等。攻擊的定義包括暴力或非人化的言論、有害的刻板印象、貶抑的陳述方式、表達輕蔑、憎惡或輕視的態度、咒罵,以及鼓吹排擠或隔離。Facebook 的仇恨言論政策主要針對以個人或群體為對象的仇恨言論或圖像進行裁決,但不包含以實體、意識形態或機構為對象的言論或圖像。舉例來說,在 Facebook 上「我恨基督徒」這句話會被判定為仇恨言論並且不被允許,因為對象指的是一群人,但「我恨基督教」因為對象指的是一種意識形態,因此不會被禁止。
Facebook BERT-based System
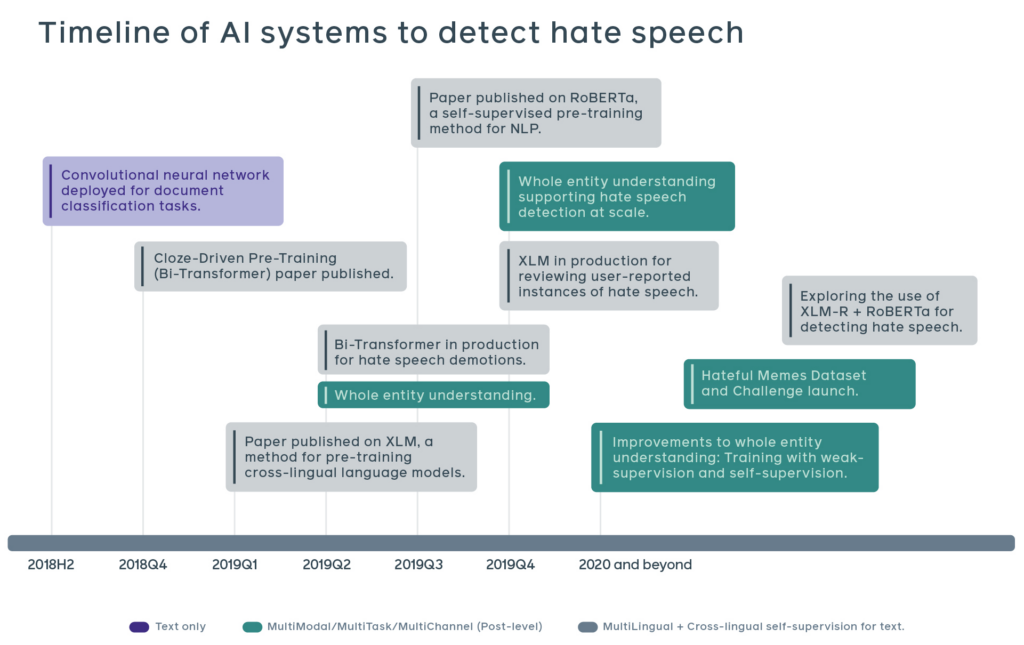
從下圖,可以看出 Facebook 大約在 2018 年開始試著導入 AI 系統輔助惡意言論判斷。在 2018Q4 Google 發表 BERT(Devlin, 2018 [ref]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[/ref])以後,一舉打開了新的 NLP 研究方向(下一個章節將會繼續介紹 BERT),在 2019、2020 年 Facebook 也發表了 XLM(Lample, 2019 [ref]Cross-lingual Language Model Pretraining[/ref]) 及 RoBERTa(Liu, 2019 [ref]RoBERTa: A Robustly Optimized BERT Pretraining Approach[/ref]),在 2019 年底發表了 XLM-R (Conneau, 2019 [ref]Unsupervised Cross-lingual Representation Learning at Scale[/ref])。
XLM 為跨語言的模型,而 RoBERTa 則是基於 BERT 的架構修改,用更大量的資料訓練、更 Robust 的模型,這幾個模型可以說是 Facebook 在 NLP 任務的基石,除了惡意言論偵測之外,雖然沒明說但我想也已經被納入 Facebook 的推薦演算法中(Google 在 2019 的時候已經在 Google Search 加入 BERT)。
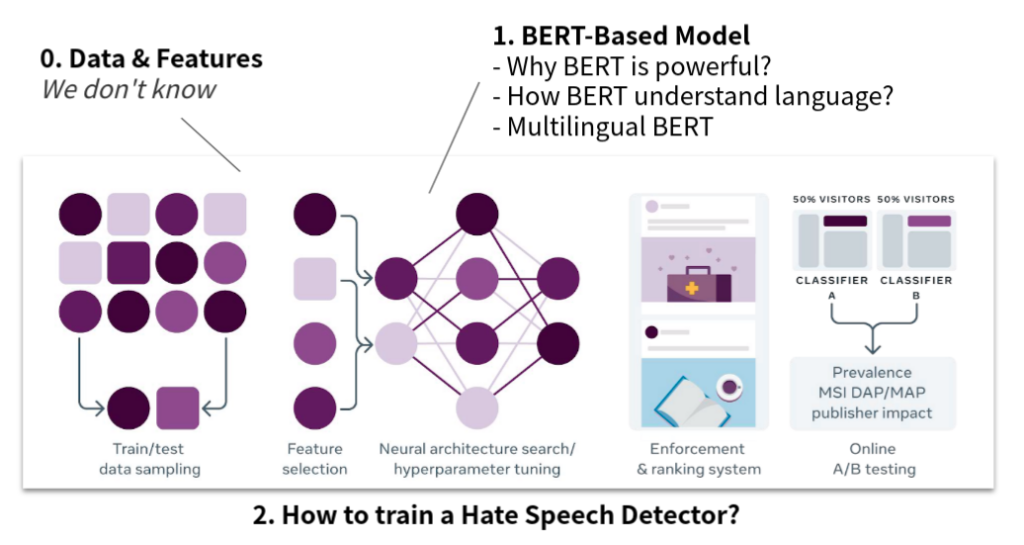
接下來,我們將用我們蒐集到的資料,介紹 Facebook 的系統,大致分為以下幾個部份,
- Data & Features:很遺憾的,我們目前沒有找到 Facebook 是如何處理惡意言論的資料,這部份比較算是實作的細節,我認為 Facebook 也不會輕易的公佈他們使用了哪些資料,可能裡面仍包含了一些倫理議題、商業機密,隱藏細節也可以避免攻擊(只要知道規則就會有人嘗試繞過)。
- 使用了哪些資料?只有文字嗎?還是有包含其他 Meta Data,如:族裔、性別、年齡、大頭貼?
- 如何處理 Feature?
- BERT-Based Model:基於 BERT 的模型是現在 NLP 的主流,我們將會討論,
- 為什麼 BERT 這麼強大?
- BERT 要怎麼理解語言?
- 多語言的 BERT 是怎麼做到的?
- Facebook 怎麼訓練 Hate Speech Detector?:實務上,Facebook 會遇到滿多特別的問題的,例如:
- 新詞彙的誕生,模型要「隨時」更新
- 對於惡意言論來說,不只要準確的刪除,同時也要考慮「最少人看到」,傳統上只能用 A/B Testing 來測試模型在 Production 時的好壞。
BERT
在 2018 年,Google 提出了 BERT(Devlin, 2018[ref]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[/ref]),在 GLUE Benchmark 上達到 State of the art 的成績, 也開啟了基於 Transformer 的 Pre-trained model 的時代,BERT 就像旋風一樣席捲了整個 NLP 領域。
BERT 的全稱是「Bidirectional Encoder Representations from Transformers」,基於 Transformer Encoder 模型。以往做 NLP 任務等序列形式的資料,通常會用 RNN 來處理,而在 2017年 Google 提出「Attention Is All You Need」(Vaswani, 2017 [ref]Attention is all you need[/ref]) 後,開始用基於 self-attention 機制的 Transformer 取代掉傳統的 RNN架構,關於 Transformer 的細節,我想還不會在這篇文章提到,還是以介紹 BERT 為主。
BERT 也是芝麻街中的人物,更早的時候有一個模型叫做 ELMO(Peters, 2018 [ref]Deep contextualized word representations[/ref]),很多基於 BERT 改良的模型都順應這個潮流,所以就形成了 NLP 界的芝麻街家族。
Why is BERT powerful?
雖然本文沒有提到實驗的數據,但可以簡單的理解為:在 2018 年 BERT 發表時,單一個 Pre-trained BERT 就可以做很多任務,而且一舉打爆了以前的模型,也大幅的改變了之後幾年的 NLP 生態(詳細的實驗可以去看原本的論文)。
BERT 為什麼這麼強大?除了 Transformer 架構之外,先介紹一個比較常見的概念–「Pre-trained model」,這已經不是新東西,但算是 BERT 如何強大的基石。BERT 先在超級大量的文本上做預訓練(Pre-train),之後再微調(Fine-tune)至下游任務(Down-stream task),也就是我們的應用場景,如:惡意言論辨識、問答系統、資訊檢索系統…等等。
舉例來說,如 Figure 1,我們可以把一個人的求學階段分成國小、國中、高中時期的通才教育,與大學之後的專才教育。
- 通才教育時,我們必須學各個科目的基礎知識,如:國、英、數、理化、社會、體育、美術等等。
- 大學後,我們選擇了一個專長,並在該專長下繼續學習。

以往如果我們想要訓練一個任務(e.g. 惡意言論偵測器),我們常常只能用相對有限的資料,去訓練我們的模型,因為有 Label 的資料是很貴的,實際的場景通常只有數千、數萬筆資料。
在 Data 量少時,模型當然還是可以 fit 這份資料,但我們更追求的是模型泛化的能力,希望在 Inference 的時候,即使 Training data 裡面沒有出現的資料模型也可以「觸類旁通」、「舉一反三」。
這就好像讓一個嬰兒直接去讀資工系、開始學程式,還是可以學到東西,但是可想而知效果通常不太好。所以先學通才教育,再學專才教育的想法應運而生,我們先讓一個小孩去學國小、國中、高中的知識,等到他是知識豐富的高三學生後,我們再把他繼續訓練在不同的專業上,因為先前的基礎,讓之後即使沒學過得知識也能更加游刃有餘。

先讓模型在大量資料上 Pre-train,再讓模型去 Fine-tune 在下游任務,已經是近年的主流作法, BERT 就是其中一個例子。
優點
- 有些資料方便取得,或已經有現成的資料集,如:ImageNet 有 14M 張影像。Wikipedia 有大量乾淨、有意義的文本資料,我們也可以很輕易的用爬蟲程式在網路上爬到一堆文本資料。
- Pre-train 模型說穿了就是在為下游任務找一個好的 Initial Weight,讓模型更 Generalizable
缺點
- 資料量太大,一般人、實驗室、公司不太可能自己 Pre-train 一個 BERT。

下表是一些 Pre-train 的數據,BERT 和 RoBERTa 使用相同的架構所以參數量相同。BERT Pre-train 在 Wikipedia 和 BookCorpus 上,共 3B 個詞,而 RoBERTa 的資料量更是 BERT 的 10 倍,需要的計算量也更大,以租用國網中心來說(一張 V100 每小時80元),要 200萬台幣才有辦法 Pre-train 一個 RoBERTa。
但!我們不需要自己訓練一個 BERT 或 RoBERTa,事實上 Google 和 Facebook 都有釋出模型的 Pre-trained weight (釋出訓練有素的高三學生),我們只需要 fine-tune 到下游任務即可(專才訓練)。
| Parameters | Pre-train Corpus | Computing | 國網中心 | |
|---|---|---|---|---|
| BERT | 110M | 3B words | 8 Nvidia V100 * 12days | 198,144 NTD |
| RoBERTa | 110M | 30B words | 1024 Nvidia V100 * 1days | 2,113,536 NTD |
How BERT understand language?
BERT 強大的地方在於經過大量的資料 Pre-train 後,具有相當程度語意理解的能力才能在下游任務表現的那麼好,從實驗看來 BERT 似乎從大量的文本中學到了像是詞性、文法等結構。接下來討論一下 BERT 是怎麼理解語言的?
Language Model
首先,先理解一下何謂 Language model。定義:「一段文字詞序列在自然語言中出現的機率」,舉例來說我們可以統計 “Today is Monday” 這句話在文本中出現的機率是 10−5 或是寫成條件機率的形式,當出現 “How are you?” 時,出現 “I’m fine, thank you, and you?” 的機率是 0.3。
P("Today is Monday")=10−5
P("I’m fine, thank you, and you?"|“How are you?")=0.3
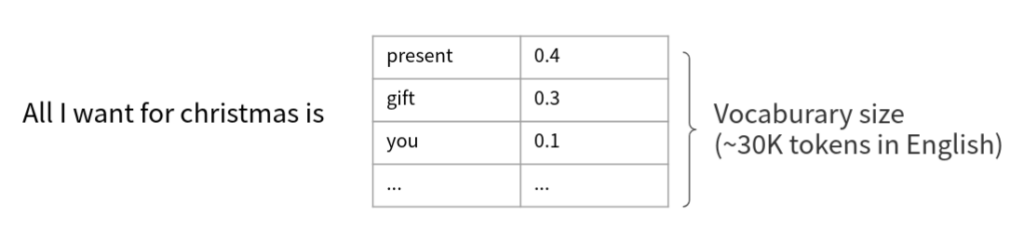
以訓練模型的角度來說,我們可以當作輸入是 “All I want for christmas is” 希望以一個 Vocaburary size 大小的分類器去預測下個字要接什麼的機率分佈。
我們常常聽到國英文老師說「多閱讀,寫作就會進步!」或網路上的鄉民說「美國小學生英文程度 >>>> 台灣大學生」,我認為這種多接觸就慢慢學會的「語感」其實就是一種 Language model。例如下面這句話:
I [mask] the bus. I [mask] late for school yersterday.
雖然這句話有些字被遮住了([mask]),但我們仍能從上下文猜到原本的句子很有可能是:
I [missed] the bus. I [was] late for school yersterday.
而不是
I [was] the bus. I [dog] late for school yersterday.。
接著猜猜看下面的兩個例子:
[mask A]是電腦處理資訊的本質,
因為[mask B]本質上是一個演算法來告訴電腦確切的步驟來執行一個指定的任務
[mask C]是大型生物分子,或高分子,它由一個或多個由α-[mask D]組成的長鏈條組成。
這四個被 mask 起來的詞,從上下文都能大概猜到大概是什麼字:
[mask A] = 演算法
[mask B] = 電腦科學
[mask C] = 蛋白質
[mask D] = 胺基酸
注意: 我們在預測 mask 的時候其實都是猜一個「機率分佈」。例如:[mask C]是大型生物分子 這句話更有可能是蛋白質、脂肪、醣、纖維素等等,但不可能是演算法、資料結構、數學等等。
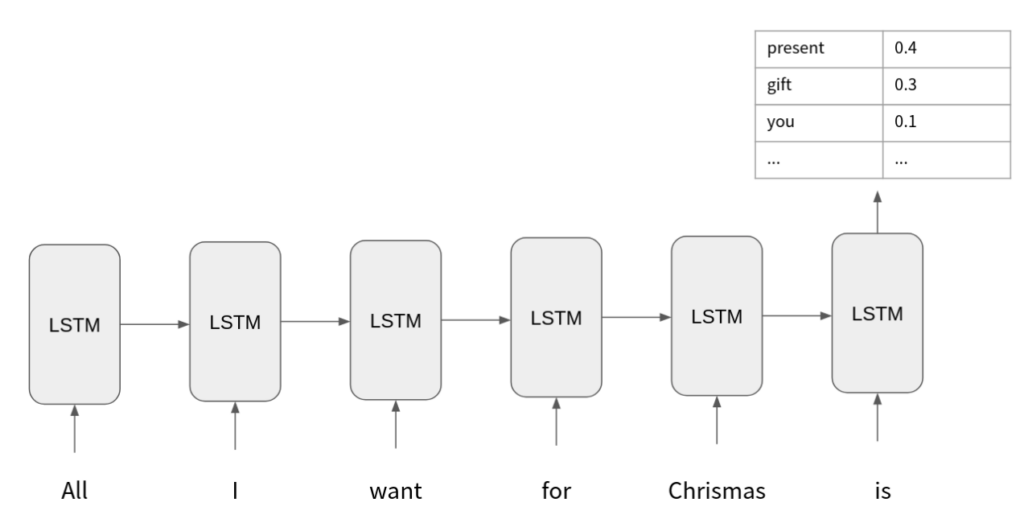
以 RNN 舉例的話,我們可以用 LSTM 去讀過 “All I want for christmas is” 這幾個 Token,然後用最後一個 Output hidden state 去預測下個字是什麼。
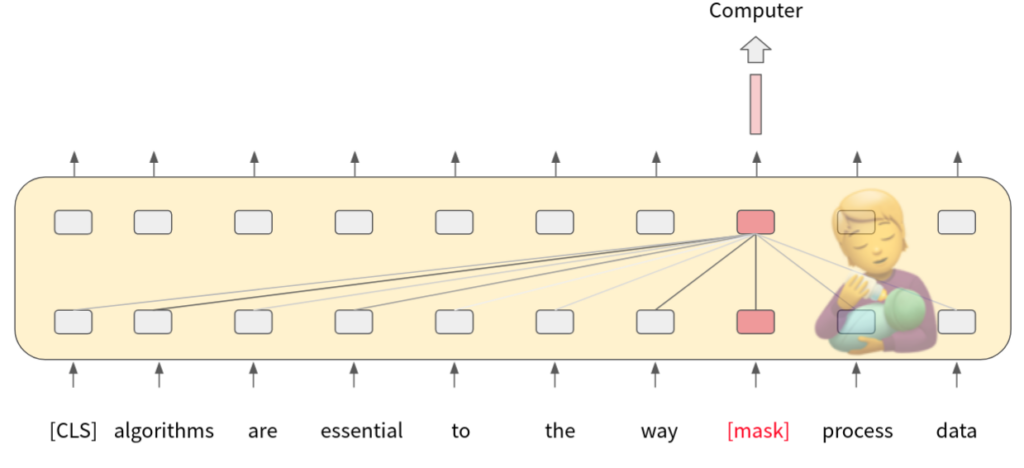
Mask Language Model of BERT
BERT 的 Pre-train 任務之一 Mask Language Model(MLM),就是讓模型學做克漏字測驗:隨機把字挖掉,換上 [mask] 這個 token,模型根據上下文(也就是 self-attention 機制),最終會輸出一根向量,我們再把這根向量經過一個 Classifier 去預測這個被 mask 的 token。白話的說就是:「模型看過上下文之後,覺得被遮掉的字應該是什麼?」
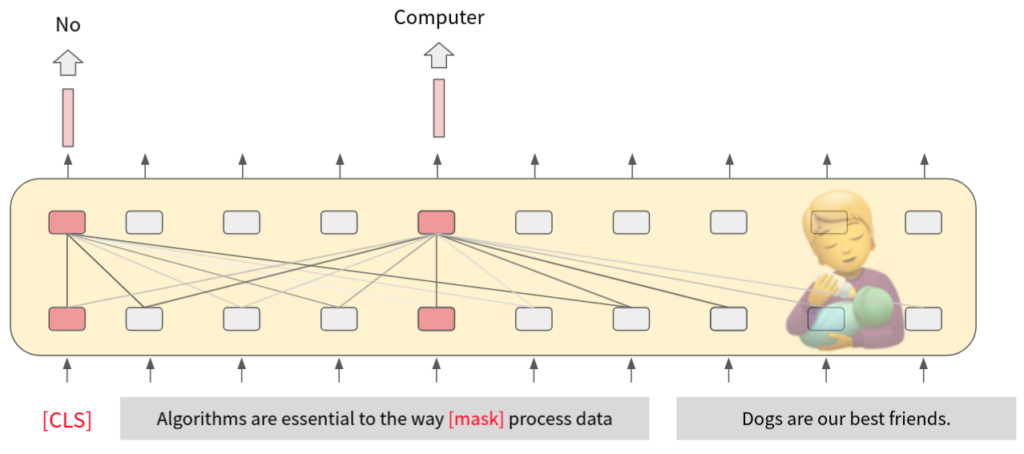
Next Sentense Prediction of BERT
在做克漏字的同時,也進行另一個任務 Next Sentense Prediction(NSP),透過在字首加上一個額外的 [CLS] token。在訓練時,以兩個句子為一組,有時隨機把第二句換成其他句子,BERT必須根據對應的 output,經過 FFN 去預測這兩句是不是接鄰的句子。白話的說就是:「模型看過句子 A,B 之後,覺得兩句話是不是語意連續的關係?」
Multilingual BERT
對於多語言的 BERT,其實就是在預訓練時看多語言的資料,同時用中文、英文、日文、德文去訓練,這樣有一些好處:
- 一個模型就能處理不同語言的資料,不需要為了各個語言去特製
- 在 fine-tune 時可以訓練在 A 語言,但測試在 B 語言。例如說,我們的資料集中只有中文的惡意言論,我們可以讓 BERT 只看中文的惡意言論,但他在測試時同時可以回答台語的問題,只因為我們在 Pre-train 時有看過台語的資料。
為什麼這樣會 work 呢? 一個詮釋是,在訓練後,不同語言代表同一語意的詞彙,其 Embeddings 是比較近的。例如說「Cat」和「貓」兩者語意接近,在 Embeddings space 會比較接近,也就達到一種「消除語言隔閡」的效果。
How to fine-tune BERT?
我們前面已經將 BERT 的兩個 Pre-train 任務 Mask Language Model 和 Next Sentense Prediction 介紹完。在應用上,其實我們完全不需要去管這兩個 Pre-train 任務,因為我們可以直接使用 Google 或 Facebook 等大公司釋出的模型,但了解其 Pre-train 方法,可以讓我們更了解怎麼去使用 BERT。
以惡意言論偵測為例,我們有一個資料集,其輸入是一個句子X="The rice dumpling is fucking delicious"y=False在 Fine-tune 時,將 [CLS] token 的 output 經過一個重新訓練的二元分類器,去預測這句話是否為惡意言論。白話一點就是:訓練一個分類器去判斷 BERT 的 output,「原來長這樣子的輸出應該就是惡意言論啊!」
由於 Pre-train 時看過超大量的文本,這個高三學生是有能力處理 fine-tune 時沒看過的資訊的。

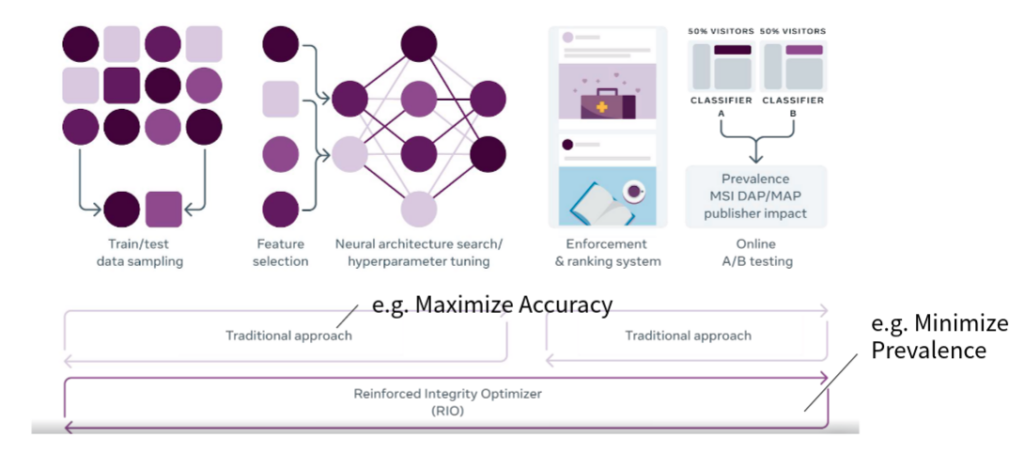
Reinforced Integrity Optimizer
How AI is getting better at detecting hate speech
我們已經可以自己用 BERT 去訓練出一個惡意言論偵測模型了,但在實務上 Facebook 還會遇到一些額外的問題:
Traditional Approach
以往我們要訓練一個模型,我們都是先整理好一組資料集,再用來訓練一個模型。模型訓練好後,在 Production 時用 A/B test 的方式去測試這個模型到底對整個社群有沒有幫助,例如去偵測 Prevalence(使用者看到惡意言論的比例) 有沒有降低。這樣的作法有一些明顯的缺點:
- 傳統的流程時間拖太長,惡意言論的變化是非常快的,尤其在 Facebook 這種每天有數億則留言和貼文的平台上
- 正確刪除不代表使用者不會看到(超惡意言論馬上刪 vs. 小違規但超多人看到),只能用 A/B Test 發覺及調整政策
- 在訓練模型時是控制的實驗和 Production 的狀況可能脫節
Reinforced Integrity Optimizer
Training AI to detect hate speech in the real world
Facebook 最新使用的方法是,直接用 Reinforcement learning 的方法,直接使用 Prevalence 當作 reward 去更新參數,雖然不知道實作細節,但這樣的方式可以讓模型快速的適應新的變化,也能更直接的提昇體驗。但這樣的作法可能更難解釋模型的因果關係。
Research Trend
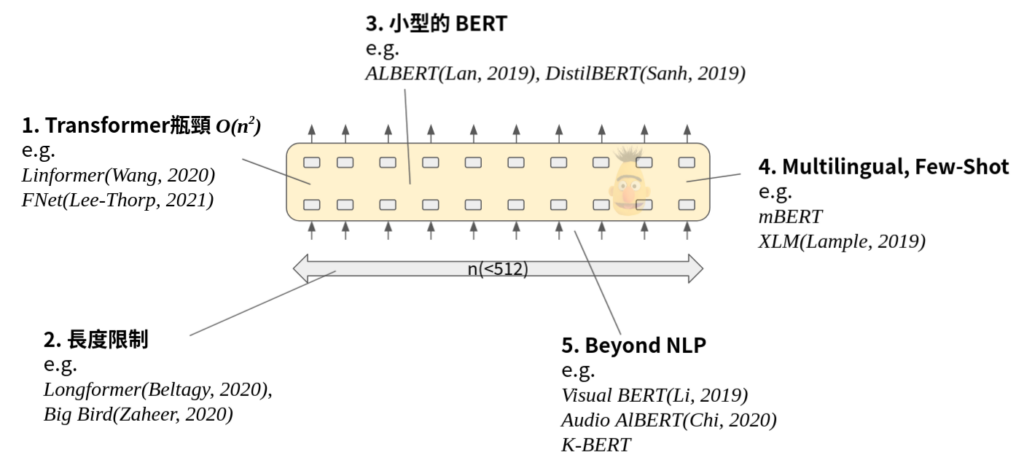
- Transformer瓶頸:Transformer 所使用的 self-attention 機制,需要計算一個 O(n2) 的 attention map,有許多研究在試圖降低這個瓶頸。E.g. Facebook 提出的 Linformer(Wang 2020 [ref]Linformer: Self-Attention with Linear Complexity[/ref]), FNet(Lee-Thorp, 2021 [ref]FNet: Mixing Tokens with Fourier Transforms[/ref])。
- 長度限制:最初的 BERT 最長只能接受 512 個 token,所以在處理 Document 時必須用其他方法處理。除了 1. 的記憶體瓶頸外,attention 機制本身的硬傷就是當 Sequence 越長,每個 token 所被分配的注意力會越少。E.g. Longformer(Beltagy, 2020 [ref]Longformer: The Long-Document Transformer[/ref]), Big Bird(Zaheer, 2020 [ref]Big Bird: Transformers for Longer Sequences[/ref])
- 小型的 BERT:在應用上 BERT 可能還是太大了,有些研究在試圖降低 BERT 的參數量,同時保留一定程度的 performance。E.g. ALBERT(Lan, 2019 [ref]ALBERT: A Lite BERT for Self-supervised Learning of Language Representations[/ref]), DistilBERT(Sanh, 2019 [ref]DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter[/ref])
- Multilingual, Few-Shot:試圖訓練多語言的模型,尤其是希望能夠 Transfer 到 low-resource 的語言上。E.g. mBERT(Delvin, 2018 [ref]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[/ref]), XLM(Lample, 2019 [ref]Cross-lingual Language Model Pretraining[/ref])
- Beyond NLP:除了文字之外,語音、圖片、影片,甚至是 Knowledge graph 都可以試著丟進 BERT 裡面。E.g. Visual BERT(Li, 2019 [ref]VisualBERT: A Simple and Performant Baseline for Vision and Language[/ref]), Audio AlBERT(Chi, 2020 [ref]AUDIO ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF AUDIO REPRESENTATION[/ref]), K-BERT(Liu, 2019 [ref]K-BERT: Enabling Language Representation with Knowledge Graph[/ref])
結論
- 有了 Pre-trained model 的幫助,下游任務不需要大量的資料也可以有不錯的成果。
- BERT 家族模型在 Facebook 的 AI 仇恨言論偵測系統扮演著重要的角色。
- Facebook 成功利用 AI 進行仇恨言論偵測,讓每位使用者有和善的社群環境。