
https://arxiv.org/abs/2203.03582

Motivation
- CTC-based models are always weaker than AED models and requrire the assistance of external LM.
- Conditional independence assumption
- Hard to utilize contextualize information
Proposed
- Transfer the knowledge of pretrained language model(BERT, GPT-2) to CTC-based ASR model. No inference speed reduction, only use CTC branch to decode.
- Two method:
- Representation learning: use CIF or PDS(LASO) to align the number of representation. Use cosine embedding loss(better than MSE loss)
- Classification learning (Similar to Improving Hybrid CTC_Attention End-to-end Speech Recognition with Pretrained Acoustic and Language Model)
Method
Representation Learning
- notation
- wav2vec2.0 encoder output: $H = (h_1, \cdots, h_M)$
- target labels: $T = (y_1, \cdots, y_N)$
Two Mechanism:
- CIF
- Integrate $h_m$ by weighted sum to collect $l_n$
- restrict the length to $N$
- Attention
- Using one layer cross attention with positional embeddings $P$ and $H$. (LASO: PDS module)
Objective: CTC loss and cosine embedding loss
$$\mathcal{L}_{cos} = k \cdot \sum _ {n=0} ^{N} (1 - \cos (l_n , e_n))$$
$$\mathcal{L}_{mtl} = \lambda \mathcal{L}_{ctc} + (1- \lambda) \mathcal{L}_{cos}$$
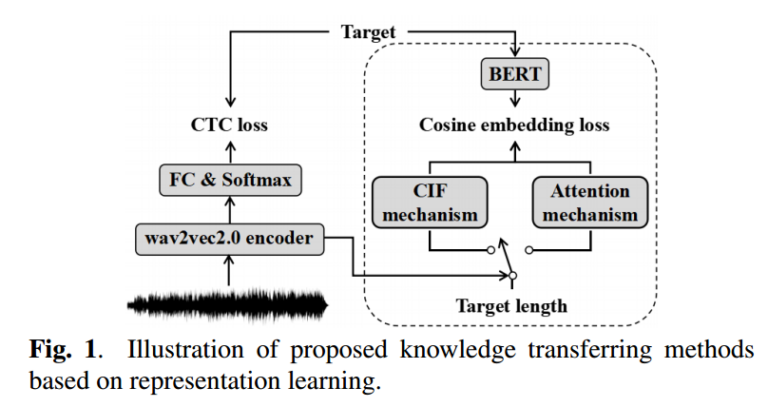
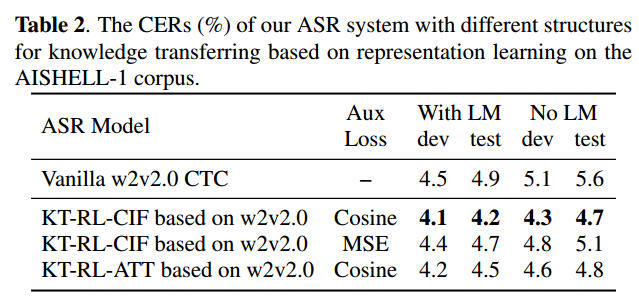
- CIF is better than ATT, but much slower
- Attention is too flexible
- extract linguistic information through a weighted sum, so the knowledge to a word may transferred to other frame. (Note: Similar to my experiment)
- Cosine is better than MSE
- Angel may be more important
Classification Learning
- Similar to Improving Hybrid CTC_Attention End-to-end Speech Recognition with Pretrained Acoustic and Language Model
- Joint training with decoder can improve the performance of CTC brach
- The speech-modal encoder output $H$ have to bridge the gap with text-modal.
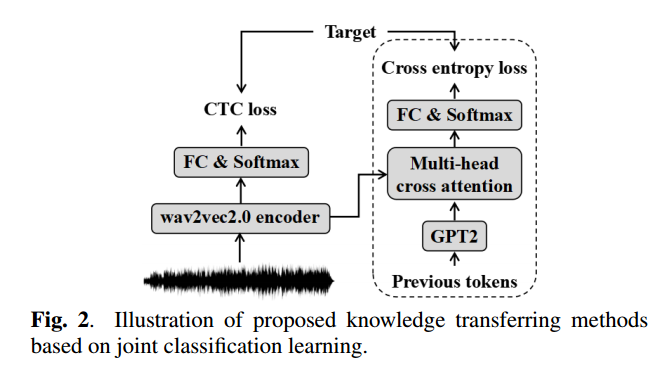
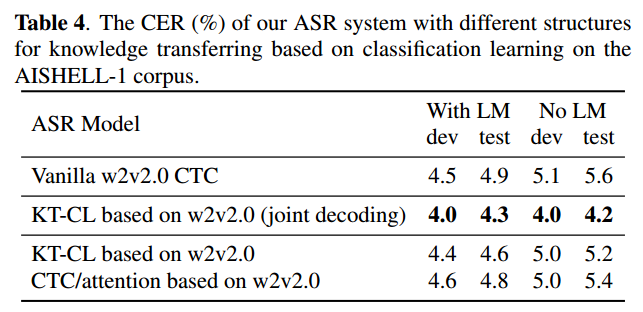
- joint training can improve performance
- KT-RL outperform KT-CL
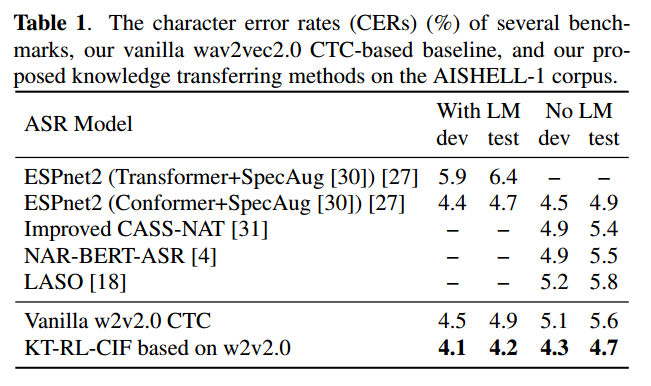
Results
- CTC-based model (no inference time reduction)
- proposed model w/o LM can surpass Vanilla Wav2vec model w/ LM (AR model)

- Bidirectional information is benefitial
Note:
- The frames which not belongs to a word are also useful information. (vs. spikes-based method)
- CIF is slower during training
- Angel may be more important