

- https://arxiv.org/abs/2006.11477
- Self-supervised speech representation
- contrastive loss: masked continous speech input -> quantized target
- quantized module: gumbel softmax(latent representation codebooks)
- wav2vec2.0 Large with 10min data: 5.2/8.6 LS-clean test
- Fairseq
- Well explained: https://neurosys.com/wav2vec-2-0-framework
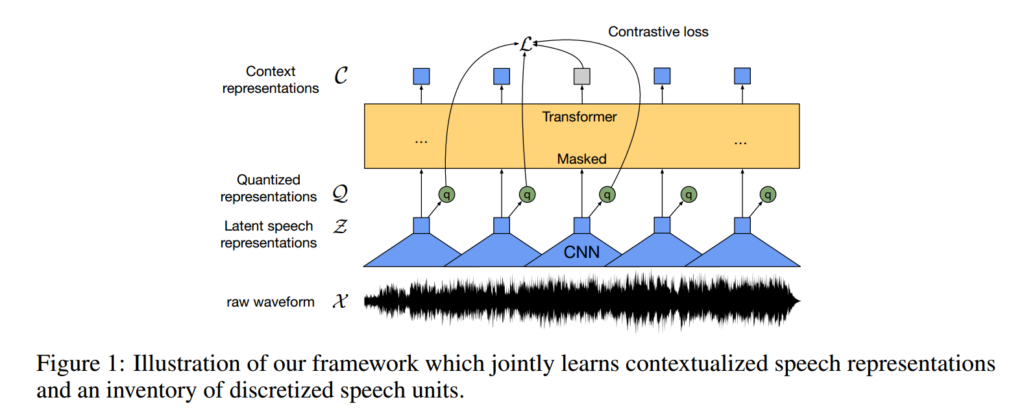
Feature Encoder(CNN)
將 raw audio \( \mathcal{X} \) encode 成 latent speech representation $z_1, \cdots, z_T$
Contextualized representation(Transformers)
- 將 $z_1, \cdots, z_T$ Mask 過後,經過 Transformers 產生 contextualized representation (看過前後)
- Note: use relitive positional embeddings
Quantization module
- wav2vec2.0 將目標表示為有限的 representation,比起學習還原連續的 output 有更好的效果
- 要怎麼離散化? 如何將 $z$ 表示成離散的表示法?
- 給定 $G$ codebooks 每本 codebook 裡面有 $V$ 個向量($e \in \mathbb{R}^{V \times d / G}$)
- 每個 $z$ 會從每本 codebook 中選擇一個向量,並連接起來 $R^{d}$
- 最後經過一層 Linear 轉換為 $q \in \mathbb{R}^f$
- 怎麼訓練?
- 使用 Gumbel softmax:可微分
- $z$ 被 mapping 到 $l \in \mathbb{R}^{G \times V}$
- $p_{g,v}$: prob of codebook $g$ entry $v$
- $$p_{g,v} = \frac{\exp(l_{g,v} + n_v)/\tau}{ \sum ^V _{k=1} \exp(l_{g,k} + n_k) / \tau }$$
- $\tau$: temperature, $n$: noise
Training
Masking
- Mask 掉一部分的 feature encoder output $Z$,(置換成學來的 mask 向量)
- 以機率 $p$ 從所有 time step 選擇,並 mask 掉其後面的 $M$ 個 token
Objective
$$ \mathcal{L} = \mathcal{L}_m + \alpha \mathcal{L}_d$$
Contrastive loss
$$ \mathcal{L}_m = -\log \frac{ \exp( sim (c_t, q_t) / \kappa) }{ \sum _ {\tilde{q} \sim Q_t} \exp (sim (c_t , q_t )/ \kappa) } $$
- $sim(a, b) = a^\top b / ||a|| ||b||$: cosine similarity
- $Q_t$: 1 positive q_t 和 $K$ 個 negative sample。從同個 utterance 中其他被 masked 掉的 time step 選
Diversity Loss
- 簡單來說就是讓 codebook 中的每個 entries 都可以被選到。Maximize entropy
- 可以得到更好的 quantized codebook
- 如果沒有這個限制,會讓模型壞掉
- i.e. 所有 representation 都選同個 entry,contrastive loss 最低
$$\mathcal{L}_d = \frac{1}{GV} \sum _{g=1} ^G - H(\bar{p}_g) = \frac{1}{GV} \sum ^G _ {g=1} \sum _{v=1} ^V \bar{p}_{g,v} \log \bar{p}_{g,v} $$
Fine-tuning
此論文中用 pretrain 好的 wav2vec2 ,加上一層 Linear,訓練 CTC loss。
Experiments
- Pretrained dataset:
- LS-960
- LV-60K
Pretraining
- Fairseq
- p = 0.065, M=10. 49% of all time steps to be masked
Base model:
- 12 Transformer layers
- 768 model dim
- 8 head
- 3072 inner dim
- Batches: cropping 250k audio sample
- batched less than 1.4m samples per GPU
- 64 V100 GPU for 1.6 days
- Adam optimizer:
- lr: $5 \times 10^{-4}$
- Base: 400k updates
- G= 2, V=320: 102.4k codewords
- d/G = 128
- K = 100
- choose the training checkpoint with lowest $\mathcal{L}_m$ on the valid set
Results
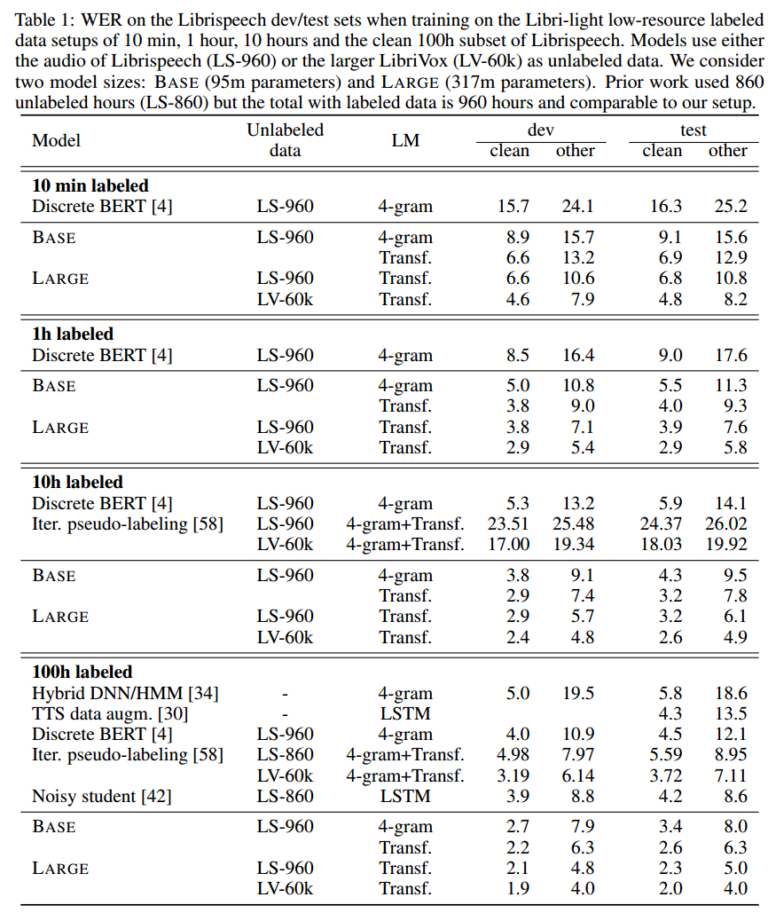
Low-Resource
- The LARGE model pre-trained on LV-60k and fine-tuned on only 10 minutes of labeled data achieves
a word error rate of 5.2/8.6 on the Librispeech clean/other test sets. - Joint learning discrete units and contetulaized representation clearly improves over previous work
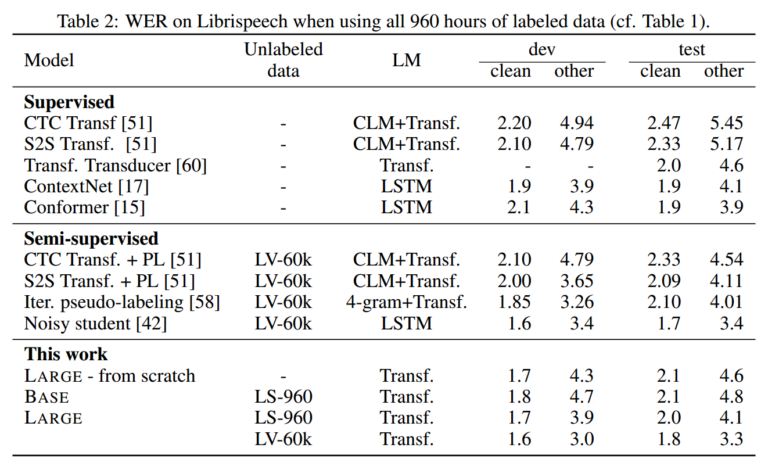
High-Resource
Ablation study
wav2vec2 最大的不同是,將 contrastive loss 的目標設為 quantized codewords
- Baseline
- Continuous input: retain more information
- Quantized target: more robust training
- Continuous target
- overfit to background

Tools: