
Can we use pre-training task other than MLM?


- https://arxiv.org/abs/2203.06906
- Proposed: Permuted Language Model(PerLM)
- Input: permute a proportion of text
- Target: position of the original token
Pretraining LM tasks
- Masked LM
- Whole word masking(wwm,):
- alleviate "input information leaking" issue
- Mask consecutive N-gram
- e.g. SpanBERT, MacBERT
Methods
- Use wwm + N-gram masking
- 40%, 30%, 20%, 10% of uni-gram to 4-gram
- Masking 15% of input words
- shuffle the position of word orders
- 10% unchanged, treating them as negative samples
- No [mask] token.
- The prediction space is the input sequence, not whole vocabulary
Given a pair of sentence $A$ and $B$, masking them in to $A^\prime$, $B^\prime$.
$$ X = \text{[CLS]}, A_1^\prime, \cdots, A_n^\prime, \text{[SEP]}, B_1^\prime ,\cdots B_m^\prime, \text{[SEP]} $$
$$ H = \textbf{PERT}(X) $$
$\tilde{H}^m$ is the candidate representations which is choosen in from previous stage. $k = \lfloor N \times 15\% \rfloor $
$$ \begin{aligned} \tilde{H}^m = \textbf{LN}(\textbf{Dropout}(\textbf{FFN}(H^m))) \\\ p_i = \text{softmax}(\tilde{H}_i^m H^\top + b), p_i \in \mathbb{R}^k \end{aligned} $$
$$ \mathcal{L} = -\frac{1}{M} \sum _{i=1}^M y_i \log p_i $$
Example
according to https://github.com/ymcui/PERT/issues/3
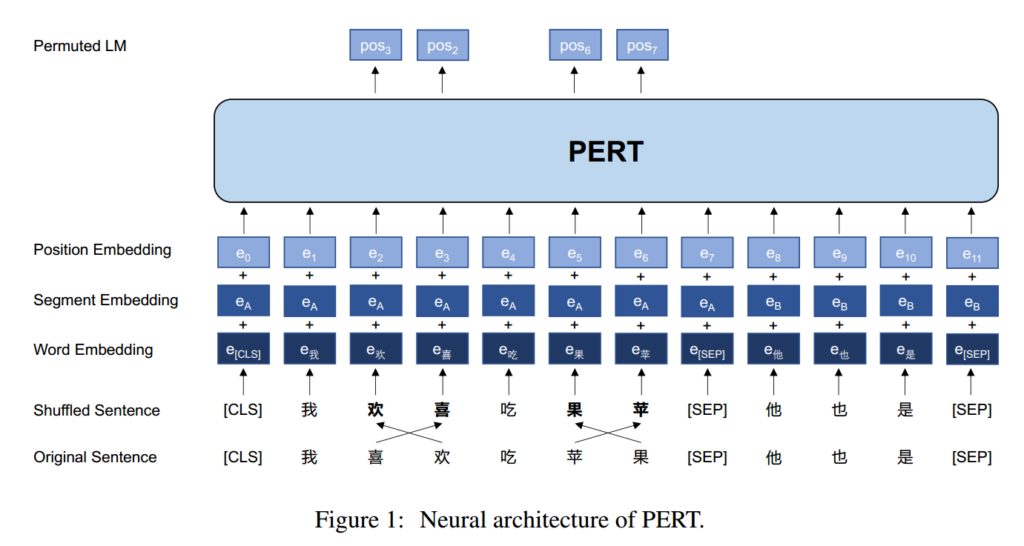
$$ \begin{aligned} H = [ H_我, H_欢, H_喜, H_吃, H_果, H_苹] \\\ \tilde{H}^m = [\tilde{H}^m_欢, \tilde{H}^m_喜, \tilde{H}^m_果, \tilde{H}^m_苹] \\\ \tilde{H}^m H^\top \in R^{k \times N} y_i = [2, 1, 5, 4] \end{aligned}$$
$y_i$ respect to the position of $H_{欢,喜,果,苹}$
Results on Chinese datasets
Machine Reading Comprehension
- moderate improvement over MacBERT, outperform others
- PERT learn both short-range and long-range text inference abilities.

Text Classification
- Do not perform well
- Conjecture: PerLM brings difficulties in understand short text compare to MRC tasks.

Named Entity Recognition
- Consistent improvement over all baselines.
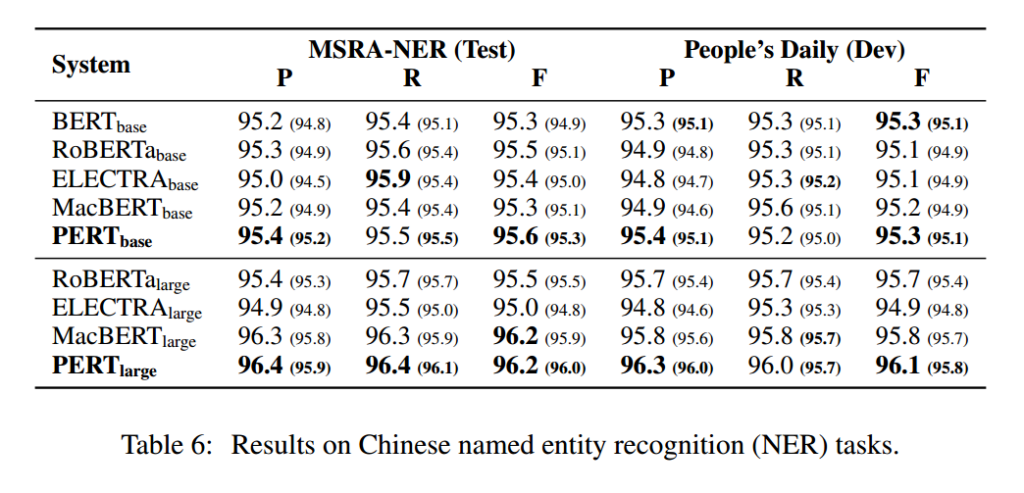
- PERT yield better performance on MRC, NER but not on TC.
- wwm + N-gram training make PERT more sensitive to word/phrase boundaries
- TC task are more sensitive to the word permutation.
- TC: is shorter, permuted word may brings meaning changing.
- MRC: is longer, some word permutation may not change the narrative flows
- NER: may not affect, NE only take a small proportion in the whole input text.
Word order recovery
- 我每天一個吃蘋果 $\rightarrow$ 我O 每O 天O 一B 個I 吃E 蘋O 果O
- consistent and significant improvements over other baseline.

Analysis
- PERT yield better performance on MRC, NER but not on TC.
- wwm + N-gram training make PERT more sensitive to word/phrase boundaries
- TC task are more sensitive to the word permutation.
- TC: is shorter, permuted word may brings meaning changing.
- MRC: is longer, some word permutation may not change the narrative flows
- NER: may not affect, NE only take a small proportion in the whole input text.
Note
- The idea came from "Permuting several Chinese characters does not affect your reading that much". I think this phenomenon is more related to "visual" but not linguistic. However, PerLM somehow performed well in other perspective.
- The results only shows first glance of this model. It showed that this pretraining task can yield some positive and negative results. Haven't showed why PerLM works or why is it powerful. The authors said they will do more experiments in the future.
- PerLM may be more effective on sequence tagging tasks (more clear word/phrase boundary?)
- may be harmful to shorter sentences.