

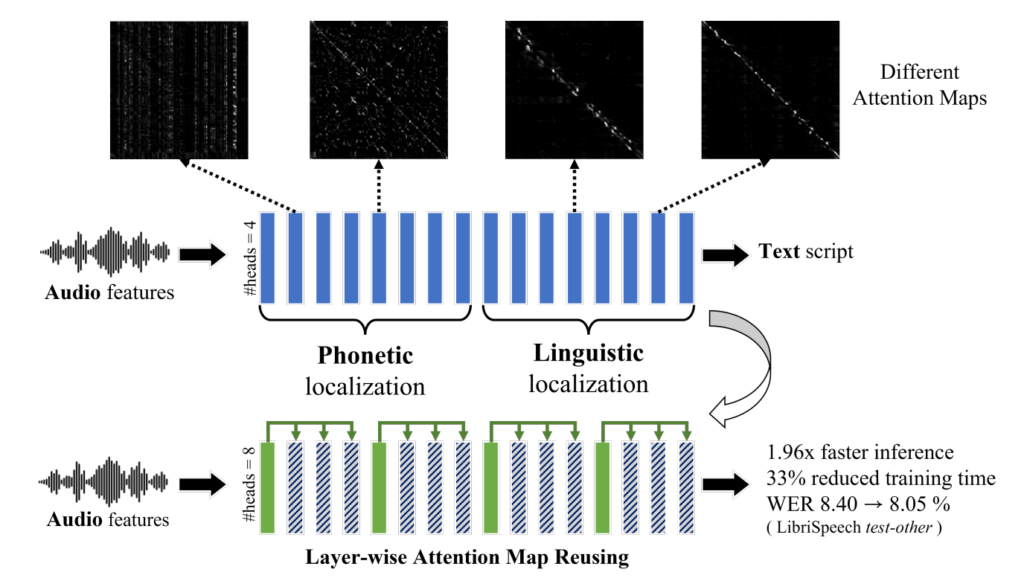
- Self-attention plays two role in the success of Transformer-based ASR
- The "attention map" in self-attention module can be categorize to 2 group
- "phonetic"(vertical) and "linguistic"(diagonal)
- Phonetic: lower layer, extract phonologically meaningful global context
- Linguistic: higher layer, attent to local context
- -> the phonetic variance is standardized in lower SA layers so upper SA layers can identify local linguistic features.
- From this understanding, can "reuse" the attention map to other layer, make the model more efficient.
To measure the diagonality: CAD(cumulative attention diagonality). To understand the behavior of each frame and other frame. $r$ is the range of attention map. Higher CAD means higher diagonality.
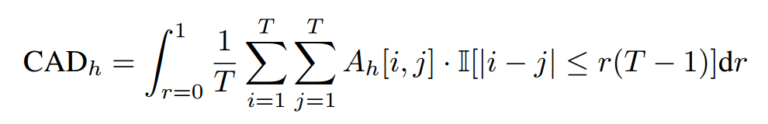
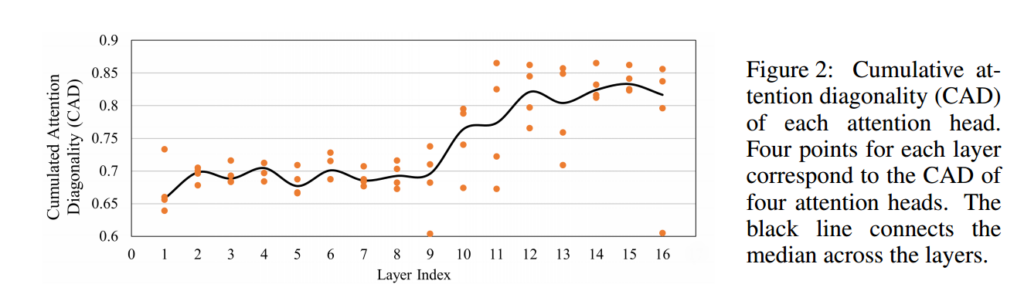
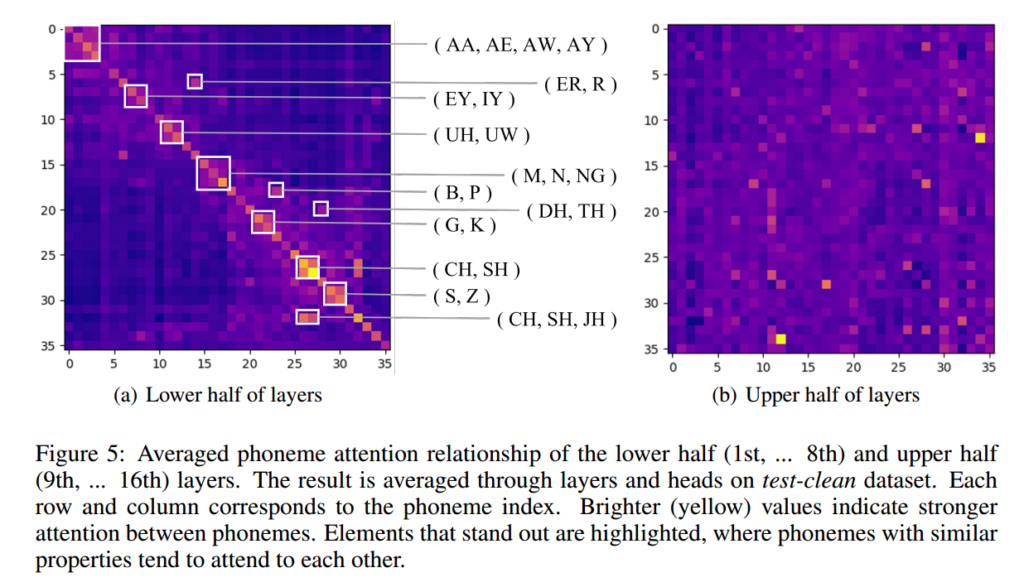
The figure shows that, SA layers can be categorize in to 2 parts:
- Linguistic: focus on local information(near in distance)
- Phonetic: focus on similar information(near in content)
Characteristic of Phonetic Localization
similar phonemes tend to assign high attention weight to each other

transform each corresponding frame more likely to others
phoneme classification by extracting the hidden layer representations from baseline model. Implies how well the hidden vectors can be distinguished. -> phoneme representations are clustered to each other.
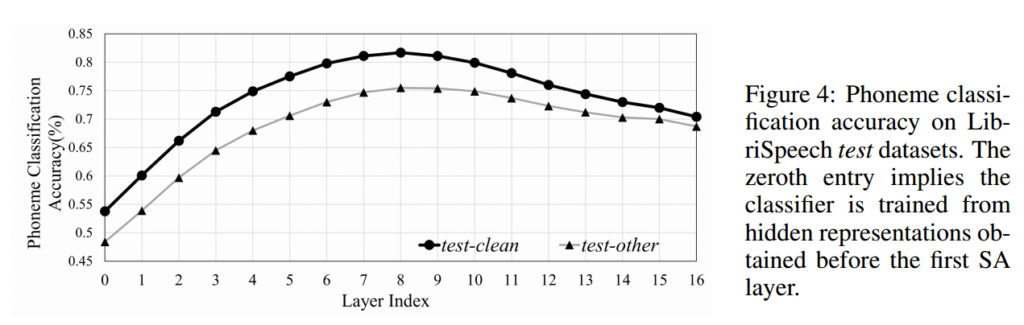
Analysis of Phonetic Attention
-> Observation: phoneme representations are clustered to each other.
To understand how phoneme attent to other phoneme:PAD(phoneme Attention Relationship)
- map $A_h[i, j]$ to $P_h[p,q]$, $p,q$ are the phoneme class correspond i-th and j-th frame.
- exclude the consecutive frames of the same class of same class.
- $C_p - E_p(i)$ indicates the subset of $C_p$ that not connect to i-th frame by consecutive class p frames.
- B.2.1 the content of p-p is not only similar but also position is similar. The effect will be too emphasize if considered neighbor frames.
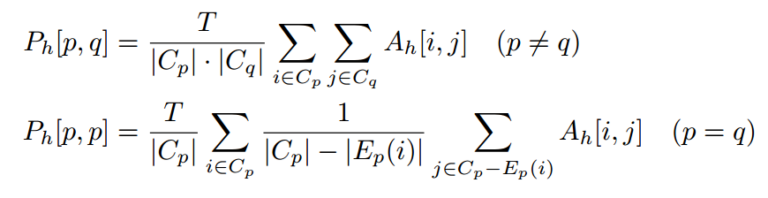
Lower layer:
- High attention on same phoneme
- Labial(B,P), velar(G,K), alveolar(S,Z) phonemes attent to each other! (唇齒舌)
-> create heterogeneous patterns
- Upper layer foucus less on similar phoneme. This is expect for the linguistic localization to perform diagonal attention map.
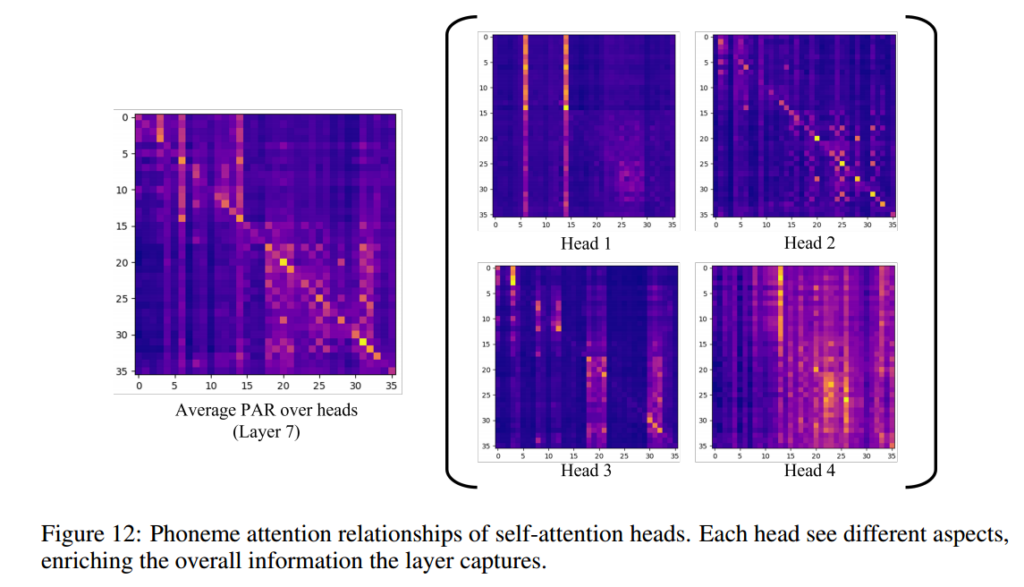
- F12. Different head focus on different phone relationship. Milti-head is useful for specialize on capturing spectific phoneme class.
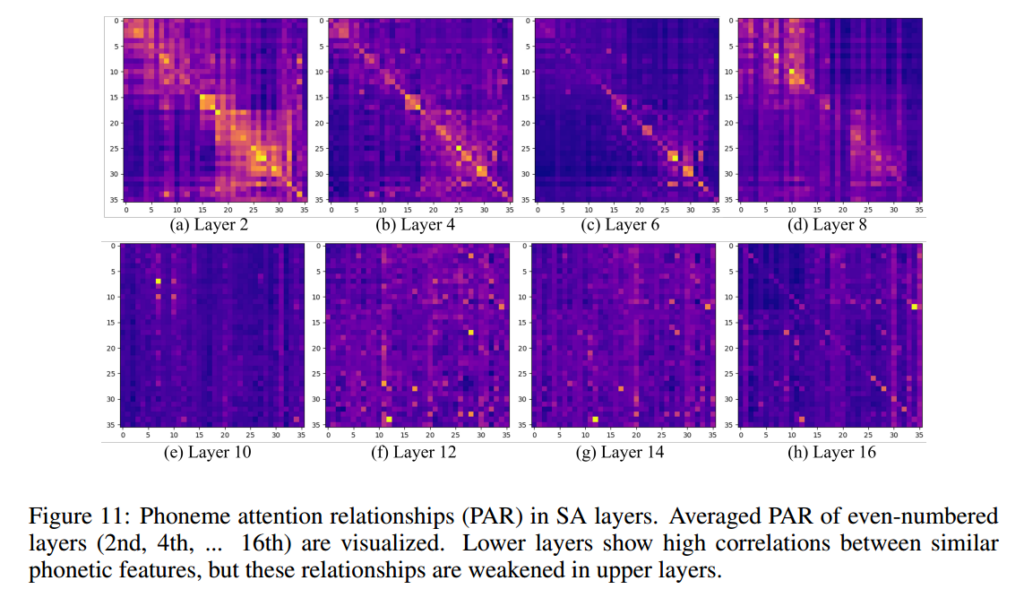
Layer-wise Attention Map Reuse
Proposed methods
Can we reuse the attention maps across multiple layers by using the two role of SA layers?